Voice cloning with Tacotron2
Introduction
This story started four years ago after a stupid bet I made with myself: I wanted to train a neural network to talk like Emmanuel Macron so that I could prank my friends and colleagues.
Spoiler alert, the experiment failed. Still, the training process remains interesting, and the outcome although useless is pretty funny.
1. Data collection
In order to train a text-to-speech (TTS) model, you need text transcripts as input data and sound files as output data.
I made a list of all President Macron's public announcements from the Elysée Youtube channel and downloaded them using yt-dlp.
I then ran an automated speech recognition (ASR) model called whisper against the results in order to get the transcripts.
This also allowed me to get timestamp data for each sentence, which I used to split the original audio into smaller clips.
All in all, it amounts to 5425 clips totalling 4 hours and 43 minutes of speech data: that's about a fifth of the reference dataset called LJSpeech.
Lastly, I dumped the clip paths and transcripts into a pipe-delimited CSV table.
2. Model selection
I chose Tacotron2 because it doesn't require any data preprocessing. Basically, what it does is that it generates spectrograms, which in turn feed a vocoder called Waveglow to output audio waveform files.
The project did require a few adjustments to make it work on Ubuntu 24.04 :
- Freeze project dependencies
- Delete tensorflow references
- Adjust librosa function calls
- Make hyperparameters a dict
You may also need to adjust some training parameters: in my case, I had to add French accents to the character set. You can find the updated project here.
3. Training results
I trained the model for 32k steps, it took about 14 hours on an NVidia RTX 3060.
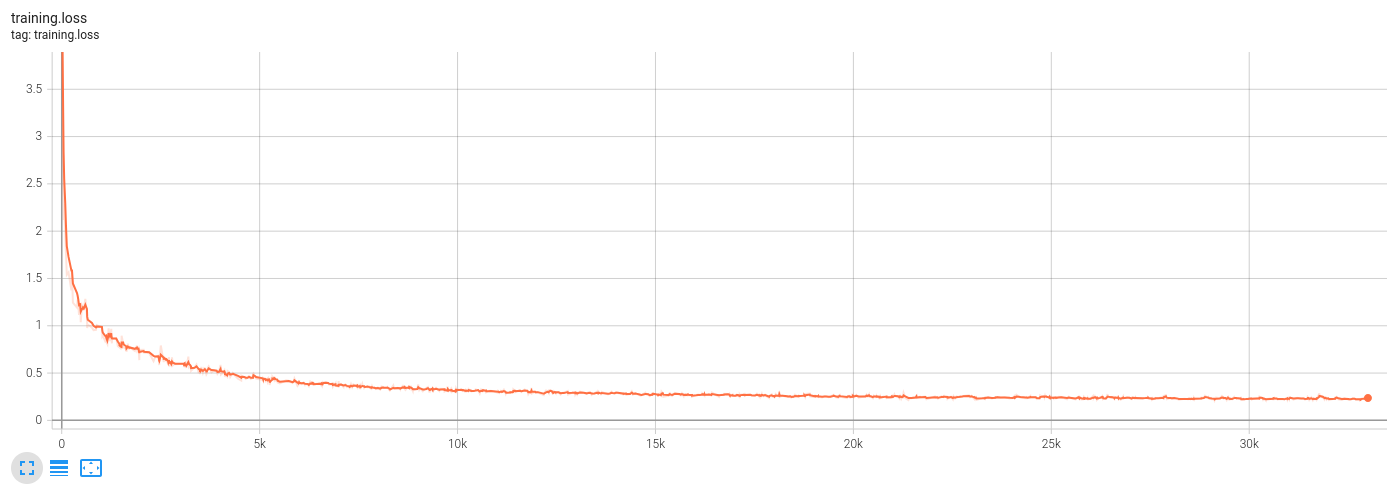
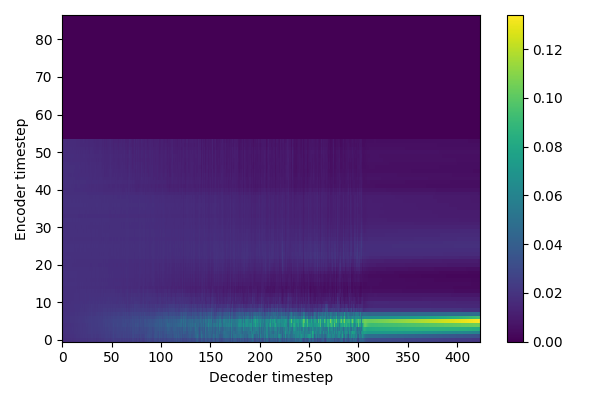
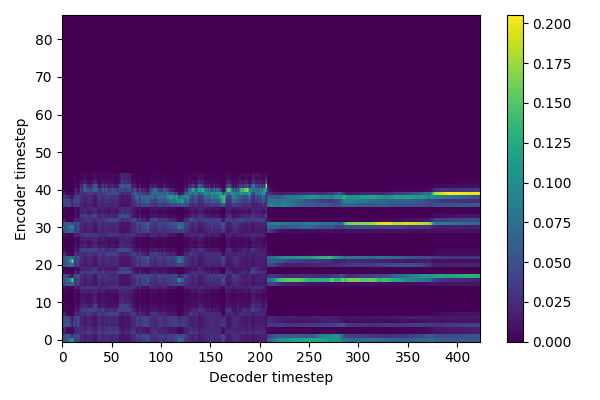
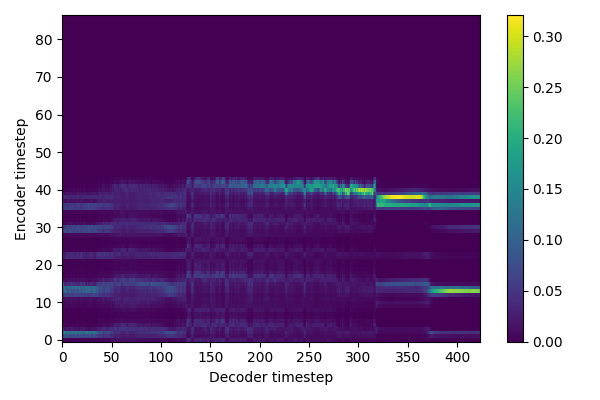
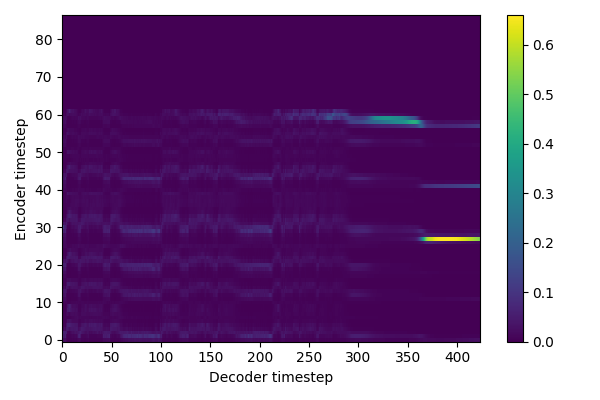
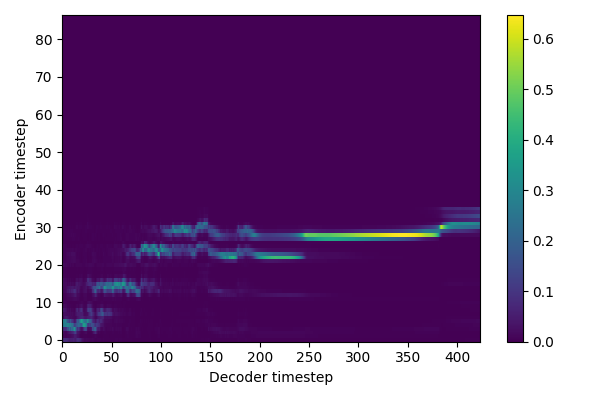
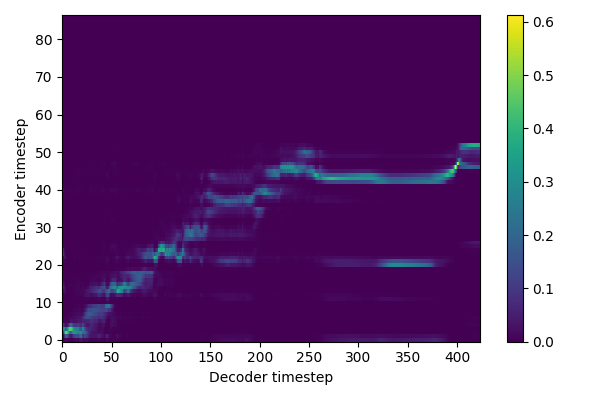
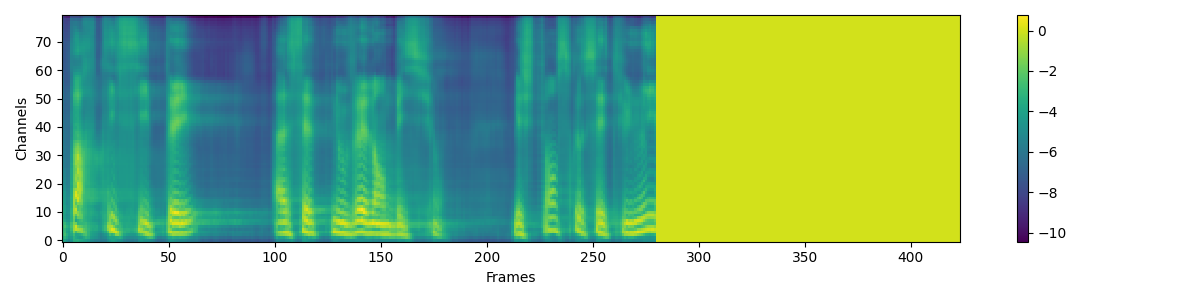
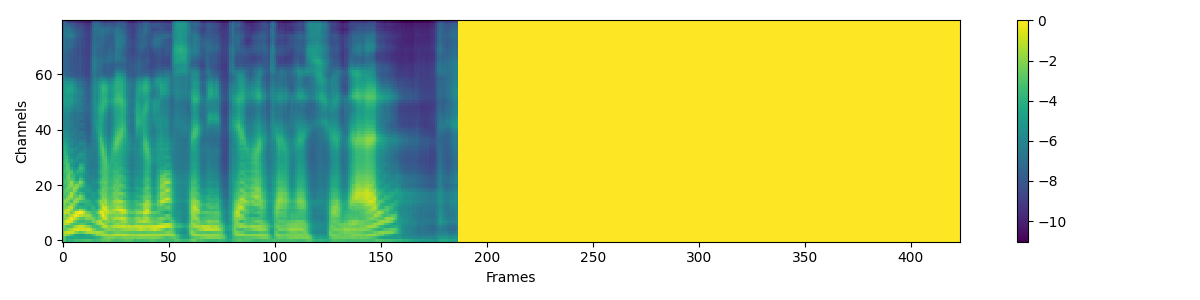
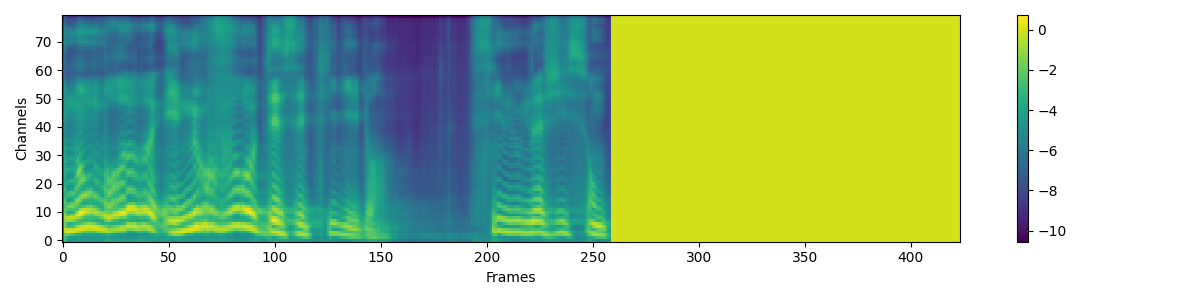
Now that the model is trained, let's try to generate some sentences ! 😁
Here is the output for "Mesdames et messieurs":
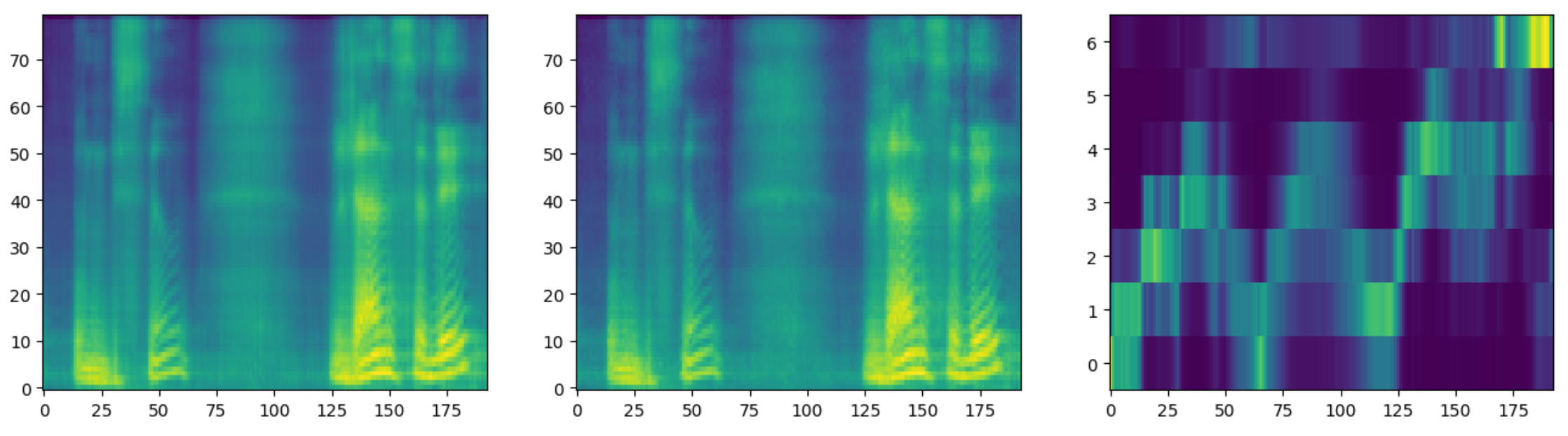
What? 🤔
The tone and the timbre are recognizable, but the content is not.
The model did not converge: could it be an alignment problem?
Conclusion
It was fun but the results are a little bit disappointing. Nowadays it's just not worth training your own TTS to clone a voice, because some open models have quite convincing one-shot voice cloning abilities like XTTS and Chatterbox.
Case in point : C'est une bonne situation, ça, scribe ?
